
【归因分析】基于随机森林的时空演变驱动因子解析



1.1 什么是随机森林?
随机森林是一种集成学习方法,通过构建多棵决策树并将它们的预测结果进行“智慧融合”——回归问题取平均值,分类问题用多数投票,从而提升模型的准确性和稳定性。简单来说,它利用“人多力量大”的思想,让多个“树”一起决策。
1.2 它是如何工作的?
·决策树:每棵树基于数据特征递归分裂,最终形成预测路径。
·随机性:
o Bootstrap采样:从数据中随机抽样(有放回),为每棵树提供不同的训练集。
o 特征随机选择:每次分裂时只考虑部分特征,增加多样性。
·结果集成:多棵树的预测结果汇总,输出最终结论。
1.3 为什么适合归因分析?
随机森林不仅能预测,还能评估每个特征的重要性。通过计算特征在减少树“不纯度”(如基尼指数或信息增益)中的贡献,它能告诉你:哪些因素对目标变化影响最大。这正是时空演变归因分析的核心需求!
Wang et al. (2022)用随机森林(RF)模型来分析NDVI和温度、降水等因素之间的非线性关系。在模型实施过程中,70%的样本(1057950个绿化的像素和14786个褐化的像素)被随机选择用于RF回归训练,剩余的30%(528975个绿化的像素和7393个褐化的像素)用于准确性验证。由于训练数据集每次都是随机抽样的,该过程被重复十次并取平均值,以确保验证结果的可靠性。
RF算法允许评估输入变量的相对重要性,或变量重要性。变量的重要性可以通过排列重要性估计如下,
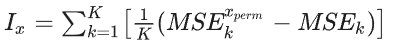
𝐼𝑥是变量x的重要性,K是决策树的数量,是变量x被消除后的第k个决策树产生的估计误差, MSE𝑘是第k个决策树包含所有变量是所产生的预测误差。𝐼x越高,说明变量x对模拟越重要。通常,所有输入变量的重要性之和为1。

图1 绿化区(a)和褐化区(b)中随机森林估计的不同因素的重要性得分(%)。X1:植被种类;X2:年均降水量;X3:年降水量变化率;X4:年均气温;X5:年气温变化率;X6:年均日照时长;X7:年日照时长变化率;X8:2000年的土地利用和土地覆盖;X9:土地利用和土地覆盖的变化;X10:年均人口密度;X11:年人口密度变化率;X12:海拔;X13:坡度;X14:坡向;X15:土壤类型;X16:岩性。
分析结果表明,在绿化区域中,高级影响变量包括年均人口密度(X10)、年均日照时长(X6)、海拔(X12)、年降水量的变化率(X3)以及年日照时长的变化率(X7),其得分在10.33%至13.63%之间(图9a)。中级影响变量为年均降水量(X2)、年气温的变化率(X5)以及年均气温(X4),得分为6.23%至8.84%。低级影响变量为年人口密度变化率(X11)、坡度(X13)、坡向(X14)和植被种类(X1)。极低级影响变量包括土壤类型、岩性、土地利用和土地覆盖。
在褐化区域中,高级影响变量包括年人口密度变化率(X11)和年气温变化率(X5),得分分别为12.40%和11.90%(图9b)。中级影响变量为年均人口密度(X10,9.84%)、年均日照时长(X6,8.98%)、年均降水量(X2,8.22%)、年日照时长变化率(X7,7.93%)、年降水量变化率(X3,7.82%)、坡度(X13,7.08%)以及海拔(X12,6.07%)。低级影响变量为年均气温(X4)、坡向(X14)以及土地利用和土地覆盖的变化(X9),得分分别为5.94%、5.19%和4.19%。极低级影响变量为土壤类型、岩性、土地利用和土地覆盖。
在绿化区域和褐化区域中,高级和中级影响因素分别有8个和9个,其总得分超过80%(绿化区域为82.60%,褐化区域为80.24%)。在这些影响因素中,绿化区域和褐化区域的共同因素包括人口统计学因素中的年均人口密度(X10)、地形学因素中的海拔(X12),以及除年均气温(X4)外的所有气候因素。此外,两个人口统计学因素X10及其变化率(X11)在绿化区域和褐化区域中分别排名第一。这表明绿化趋势和褐化趋势主要取决于人类干扰,而NDVI变化的程度可能与海拔相关的气候变化高度相关。
import pandas as pdfrom sklearn.ensemble import RandomForestRegressorfrom sklearn.model_selection import train_test_splitimport matplotlib.pyplot as plt# 加载数据(假设文件名为'vegetation_data.csv')data = pd.read_csv('vegetation_data.csv')# 定义自变量和因变量X = data[['temperature', 'precipitation', 'population', 'land_use']]y = data['NDVI_change']# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 构建并训练随机森林模型rf = RandomForestRegressor(n_estimators=100, random_state=42)rf.fit(X_train, y_train)# 评估模型性能print('测试集R²:', rf.score(X_test, y_test))# 获取特征重要性importances = rf.feature_importances_feature_names = X.columnsfeature_importance_df = pd.DataFrame({'feature': feature_names, 'importance': importances})feature_importance_df = feature_importance_df.sort_values(by='importance', ascending=False)# 可视化特征重要性plt.figure(figsize=(10, 6))plt.barh(feature_importance_df['feature'], feature_importance_df['importance'])plt.xlabel('重要性')plt.title('特征重要性分析')plt.show()
随机森林在时空演变归因分析中展现了独特优势:它不仅能处理复杂数据,还能直观揭示驱动因素的重要性。无论是科研还是决策,这一工具都能助你更深入地理解变化背后的故事。
参考文献:
Wang, Y., Chen, X., Gao, M., & Dong, J. (2022). The use of random forest to identify climate and human interference on vegetation coverage changes in southwest China. Ecological Indicators, 144, 109463. doi:https://doi.org/10.1016/j.ecolind.2022.109463

点击下方 关注我们